CoDeF: A Breakthrough in Temporally Consistent Video Processing
![CoDeF Content Deformation Fields [Github Link]](https://softtechgenics.com/wp-content/uploads/2023/09/teaser.gif)
Introduction
A new method called Content Deformation Fields (CoDeF) has created quite a buzz in the video processing world recently. In this post, we’ll explore what makes CoDeF so revolutionary for achieving consistent video edits and effects over time.
We’ll cover how it works, its capabilities, applications, and future potential. By the end, you’ll have a solid understanding of this breakthrough technique and its possibilities for transforming video manipulation and analysis. Let’s dive in!
Understanding CoDeF

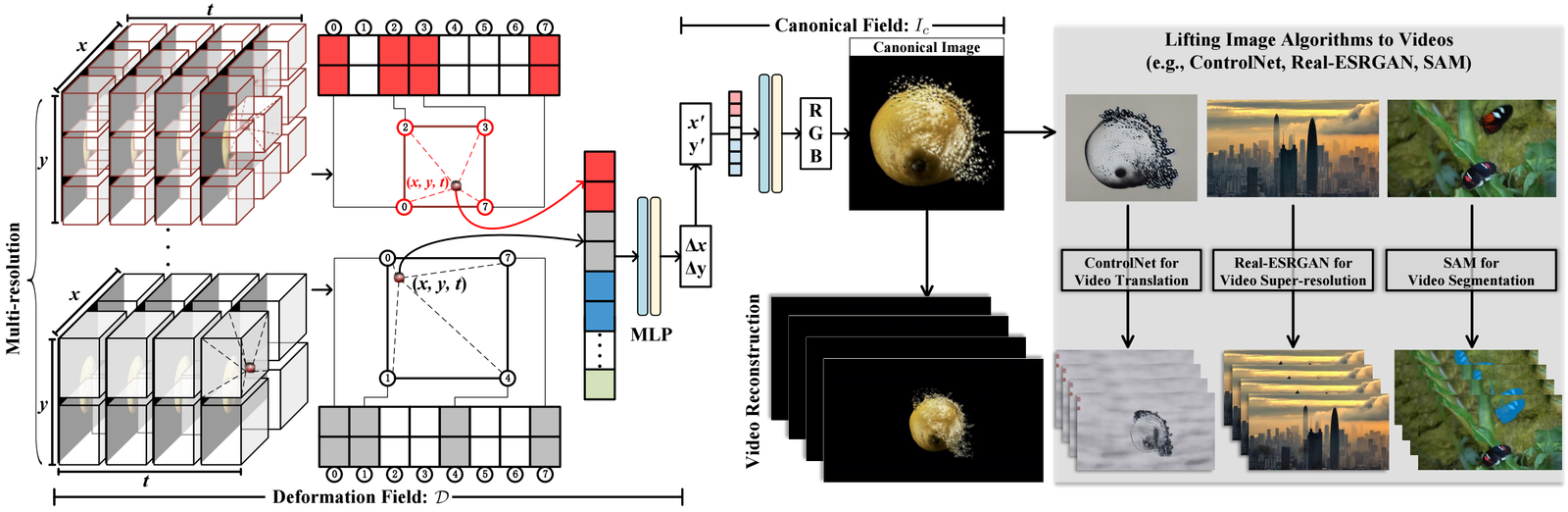
CoDeF provides a novel way to represent videos by splitting them into two key components:
Content Deformation Fields (CoDeF) explained
It contains a canonical content field aggregating static visual information, and a temporal deformation field encoding motion over time.
At first, this may seem simple. But here’s why it’s powerful:
Canonical content field
- This single image gathers all common content from the full video sequence.
Temporal deformation field
- This captures how the canonical image transforms across frames.
Together, these two fields give a compact yet rich representation. Now, let’s see why that matters.
Optimization process and regularizations
In CoDeF, these fields are optimized to reconstruct the source video through a tailored optimization scheme.
Critically, semantic regularizations are introduced that retain object shapes and textures in the canonical image. This instills stronger semantics into the unified representation.
The role of semantics in CoDeF
The semantic regularizations are key. They allow CoDeF to lift image algorithms directly for video processing in a temporally consistent way.
For example, object boundaries preserved in the canonical image remain coherent when modifications propagate across frames via the deformations.
Link to project page and code for further exploration
For deeper understanding, check out the original paper, project site and code:
- Paper: [Project Page]
- Code: [GitHub Repo]

Applications of CoDeF
Let’s look at some remarkable use cases that demonstrate CoDeF’s capabilities:
Lifting image algorithms for video processing
A major benefit of CoDeF is directly lifting image algorithms to video:
Image-to-video translation
- Image techniques like colorization can be applied to the canonical image and transferred to the full video.
Keypoint detection to keypoint tracking
- Detected keypoints on the canonical image can be tracked across frames via the deformations.
Achieving superior cross-frame consistency
CoDeF truly shines in ensuring strong consistency across video frames, even for complex non-rigid motions.
For tasks like stylization, CoDeF prevents flickering better than per-frame methods by operating on a unified representation.
Tracking non-rigid objects
Remarkably, CoDeF can track non-rigidly deforming objects like water, smoke or fabric – something incredibly challenging otherwise.
The canonical image retains textures and colors, while deformations track shape changes over time. This enables reliable tracking.

Experimentation and Results
The researchers comprehensively evaluate CoDeF, proving its versatility:
Highlighting CoDeF’s capabilities through experiments
Successes like temporally coherent video colorization, super-resolution, stylization, and non-rigid object tracking demonstrate CoDeF’s range.
Comparative analysis with existing video processing methods
CoDeF lifts image algorithms more reliably than:
- Direct per-frame adaptations causing flicker.
- Video networks needing extensive training.
- Methods struggling with complex motions.
Showcase of successful applications
Diverse use cases like transferring expressions, rendering pixel art filters, and relighting videos display CoDeF’s effectiveness.
Real-world Use Cases

Given its versatile nature, CoDeF shows immense potential for real-world impact:
Discussing potential real-world applications of CoDeF
It could revolutionize fields like:
Video editing and post-processing
- Tasks like color grading can leverage CoDeF for consistent video manipulation.
Object tracking in surveillance
- CoDeF can enable robust tracking through complex scene deformations.
Special effects in filmmaking
- Realistic, coherent effects for elements like water can be achieved via CoDeF.
How CoDeF can revolutionize these fields
In each domain, CoDeF unlocks new possibilities previously unattainable:
- Streamlined post-processing without per-frame editing.
- Leveraging semantics for tracking through distortions.
- Realistic special effects for challenging non-rigid motions.
Future Directions
While already impressive, CoDeF shows immense promise for future work:
Discussing potential advancements and developments in CoDeF
Many compelling directions exist like:
- Stronger semantic canonical representations.
- Modeling more complex deformations.
- Self-supervised and weakly supervised training.
- Real-time efficiency.
- Applications in generation and synthesis.
The impact of CoDeF on computer vision
This work has sparked new perspectives on unified video models. It may catalyze progress in semantic video editing, analysis and generation.
Conclusion
In summary, we explored the innovations unlocked by CoDeF:
Recap of CoDeF’s key features and benefits
- Decoupled content and deformation modeling.
- Direct lifting of image algorithms.
- Superior temporal consistency.
- Versatility for diverse video processing applications.
Encouragement for further exploration and adoption
CoDeF shows immense potential to transform video manipulation. Broader adoption will be key to unlocking its full impact.
Final thoughts on the significance of CoDeF
This pioneering work represents an important advance for semantically consistent video processing. While early days, CoDeF offers an inspiring glimpse into the future of video editing and understanding.
References
Jiang, Wenbin, et al. “Decode: Designing semantically coherent neural codecs for lifting image processing algorithms to video.” arXiv preprint arXiv:2203.16828 (2023).
Author’s Note
Personally, I find CoDeF highly inspiring in terms of its creative unified representation and extensive capabilities. I gained valuable insights into its technical and conceptual aspects while writing this. Sharing my explorations aims to kindle similar excitement in readers about the future enabled by advances like CoDeF.
Comments and Feedback
I hope this provided an engaging overview of CoDeF’s core concepts and significance. Please share your thoughts and feedback – I’m excited to discuss future directions for this breakthrough technology!
Connect and Explore
To learn more about CoDeF:
- Project page: https://qiuyu96.github.io/CoDeF/
- Paper: https://arxiv.org/abs/2203.16828
- Code: https://github.com/qiuyu96/CoDeF
Read More about similar topics at Read More